1 ����
δ��ս��������Ϣ������Ϊ����ս�����������������ǣ������������ϵ�������ӷ��ء����θ����ش���Ϣ��ս������Ҫ���������������ʱ���ʵء�������Ϊ��ս�����ṩ���ʱ��ϣ���������������ϵĿ����ԡ������Ժ�ȷ�Ե�����˸���Ҫ��RFID(Radio Frequency Identification)��һ�ֻ�����Ƶԭ��ʵ�ֵķǽӴ�ʽ�Զ�ʶ�����������似���ɿ��ԺͿ����Ե���ߣ��ѱ���Ӧ���ھ�������������ʹ����������Ϣ�ܹ�ȷ���ɿ������١���Ч�Ĵ��䡢�ɼ��������ͽ������������RFID��д�����ԣ�����ȷ�IJɼ���Ϣ��Ҫ���д�����ڽ϶̵�ʱ���ȡ�϶�ı�ǩ��
Ȼ������д����ÿ����ǩͨ�Ŷ���ͨ����ͬ���ŵ����������ǩ�Ͷ�д��ͨ��ʱ��������źű�Ȼ�ᷢ����ͻ���⽫ʹ�ö�д����������ǩ[1]��ͨ���أ�������������Dz��÷���ͻ�㷨��Ŀǰ�ķ���ͻ��RFID��ǩ�㷨����ϵͳģ��������Է�Ϊ�����ࣺ����͵ĺ�ȷ���͵��㷨[2]��ALOHA���㷨��������㷨������Ҫ��һ���㷨�������ڸ����ۺ�ʱ�ֶ�ַ��ԭ�����������ǩ���ź��ڶ��ʱ϶�ڷ���[3]�����ǣ�����ǩ��������ʱ��ijЩ��ǩ���ںܳ�ʱ����Ҳ���������������˱�ǩ©������ȷ�����㷨���д����Ե��Ƕ�������[4]��ѯ�����㷨[5]�����ж��������㷨������Capetanakis[6]�����������������ַ���⣬������Hush��Wood[4]������Ч��������RFID��ǩ����ͻ�����������㷨�����з�����ͻ�ı�ǩ����طֽ�Ϊ�����Ӽ���һ���Ӽ�Ϊ���ͣ���һ���Ӽ�Ϊ�ȴ��������ֽ�ֱ���������б�ǩ����Ȼ�����������㷨��ȡ��ǩ��ʱ����������ӣ����������ڷ��ѵ�ԭ����������Ч�����ǩ©�����⣬�ر�ǩ��������ʱ��
���ĴӼ��ٱ�ǩ��ȡʱ��������ڶ��������㷨�Ļ����ϣ����һ�־����Զ����ȼ�����ı�ǩ����ͻ�㷨�����㷨�봫ͳ�����������㷨����ͬ���ǣ��������Զ���Ϊ������ͻ��ÿ����ǩ����һ�����ȼ��������б��������ȼ��ı�ǩ����ʱ������˳�����д��ͨ�š���ˣ����㷨������Ч�ر����ǩ�ij�ͻ�Ϳ��д������Ӷ������˱�ǩ��ȡʱ�䡣������֤������������������������ķ���ͻ�㷨�Ķ�ȡʱ��Ҫ�����ڴ�ͳ�Ķ����������㷨�����ĵ�ʣ�ಿ�ְ������£��ڶ����ֽ��ܾ����Զ����ȼ�����ķ���ͻ�㷨���������ֶԸ��㷨�����ܽ��з��������IJ��ַ��������������һ���ָ������ۡ�
2�Զ����ȼ������RFID��ǩ����ͻ�㷨
2.1 ϵͳ����
�ڱ����У�ϵͳ�ɶ�д�������ɸ���ǩ���ɣ����ȶ�д�����������ǩ���յ�����������ݣ�����д���ɹ����յ���ǩ���͵����ݣ����ȡ��ǩ��Ϣ������
һ���������������ι���
1) ��ʼ�Σ��ýΣ���д��������ѯ����ڶ�д�����Ƿ�Χ�ڣ����н��յ�����ı�ǩ���������ݡ�
2) ���ݷ��ͽΣ��ڸýΣ����յ���ѯ����ı�ǩ���������ݣ��������ݵ�˳������ʼ�����ȼ��Ŷ�������������ͻ����ִ���Զ����ȼ�������㷨�����·������ݷ���˳��
3) �����Σ����б�ǩ�����ݾ��ѷ�����ϣ�һ�������ڽ�����
��ǩ�ӿ�ʼ�������ݵ�����������Ϊһ��ʱ϶����![]() ��ʾ������ÿ��ʱ϶�ڱ�ǩ���ݷ��͵�״̬����ÿ��ʱ϶����Ϊ������������
��ʾ������ÿ��ʱ϶�ڱ�ǩ���ݷ��͵�״̬����ÿ��ʱ϶����Ϊ������������
1�� ��ʱ϶ �ڸ�ʱ϶��û�����ݷ��ͣ���![]() ��ʾ
��ʾ
2�� �ɶ�ʱ϶ �ڸ�ʱ϶�����ҽ���һ����ǩ���ݷ��ͣ���![]() ��ʾ
��ʾ
3�� ��ͻʱ϶ �ڸ�ʱ϶���ж������ϵı�ǩ���ݽ��з��ͣ���![]() ��ʾ
��ʾ
�ڸ��㷨�У��涨�������ֺ�
1)
���ȼ��ţ�ÿ����ǩ��ӵ��һ������Ψһ�����ȼ��ţ���ʼ���ȼ���Ϊһ����������������ȼ��涨�˱�ǩ��һ���������ں�ʱ�������ݣ����ȼ�Խ�������Խ�����ʱ϶�ڷ������ݡ����ȼ�����![]() ��ʾ��
��ʾ��
2)
ָ��ţ�ָ������ųɹ��������ݵı�ǩ��Ŀ�仯���仯����ÿ�������ڵij�ʼʱ��ָ��ž�Ϊ0���Ժ�ÿ�ɹ�����һ����ǩ���ݣ�˳���1��ָ�����![]() ��ʾ��
��ʾ��
3)
3) ![]() �ţ�ÿ����ǩ��ӵ��һ��Ψһ��
�ţ�ÿ����ǩ��ӵ��һ��Ψһ��![]() �ţ���
�ţ���![]() �Ŵ�����ÿ����ǩ�����ݣ���
�Ŵ�����ÿ����ǩ�����ݣ���![]() ���ڶ����ڵ��κ�ʱ�������ı䣬��ǩ���д�����͵����ݾ���
���ڶ����ڵ��κ�ʱ�������ı䣬��ǩ���д�����͵����ݾ���![]() �š�
�š�
4)
������ʶ�ţ�ֻҪָ��ų���������ʶ�ţ���ô�ͱ������б�ǩ���ѱ���ȡ��ϣ�һ����д���ڽ�����������ʶ����![]() ��
��
����ÿ����ǩ�Ƿ������ݵ�״̬����ÿ����ǩ����Ϊ��������״̬
1)
�����ij����ǩ�����ȼ��ŵ���ָ���ʱ���ñ�ǩ���ڼ���״̬���ڸ�״̬�£���ǩ���Է������ݣ���![]() ��ʾ
��ʾ
2)
�ȴ�����ij����ǩ�����ȼ���С��ָ���ʱ���ñ�ǩ���ڵȴ�������״̬���ڸ�״̬�£���ǩ���������ݣ���![]() ��ʾ��
��ʾ��
3)
���ߣ���ij����ǩ�����ȼ��Ŵ���ָ���ʱ���ñ�ǩ��������״̬����״̬�����ñ�ǩ�ѷ������ݣ�ֱ���¸����������ٶ����ٷ������ݣ���![]() ��ʾ��
��ʾ��
���ϵ�ϵͳ�������ı�ʾ�����������1
��1 ϵͳ�����ı�ʾ��������
|
ϵͳ���� |
��ʾ�� |
���� |
|
ʱ϶ |
|
��ǩ�ӷ������ݵ�������ʱ�� |
|
��ʱ϶ |
|
ʱ϶�������ݷ��� |
|
�ɶ�ʱ϶ |
|
ʱ϶�ڽ���һ�����ݷ��� |
|
��ͻʱ϶ |
|
ʱ϶���ж������ϵ�����ͬʱ���� |
|
��ǩ�� |
|
��д����Χ�����б�ǩ������ |
|
���ȼ��� |
|
�涨��һ���������ں�ʱ�������� |
|
ָ��� |
|
�ɹ����ͱ�ǩ����Ŀ |
|
��ǩ���ݺ� |
|
������ǩ���� |
|
����״̬ |
|
��״̬�£���ǩ���Է������� |
|
�ȴ�״̬ |
|
��״̬�£���ǩ�ȴ������� |
|
���� |
|
��״̬�£���ǩ�ѷ������� |
2.2 �㷨����
1��ʼʱ��ϵͳ��![]() Ϊ0�����б�ǩ��
Ϊ0�����б�ǩ��![]() Ϊ
Ϊ![]() ��һ�����������д��������ѯ������н��յ�����ı�ǩ����һ��ʱ϶��ʼʱִ����Ӧ�IJ�����
��һ�����������д��������ѯ������н��յ�����ı�ǩ����һ��ʱ϶��ʼʱִ����Ӧ�IJ�����
2ʱ϶��ʼʱ����![]() >
>![]() ����תΪ7������תΪ3��
����תΪ7������תΪ3��
3����![]() С��ϵͳ
С��ϵͳ![]() �ı�ǩ����״̬
�ı�ǩ����״̬![]() ������
������![]() ����
����![]() �ı�ǩ����״̬W������
�ı�ǩ����״̬W������![]() ����
����![]() �ı�ǩ����״̬
�ı�ǩ����״̬![]() ����ֻ��һ����ǩ��
����ֻ��һ����ǩ��![]() ����ϵͳ
����ϵͳ![]() ��ת��4����û���κα�ǩ��
��ת��4����û���κα�ǩ��![]() ����ϵͳ
����ϵͳ![]() ��ת��5�������������ϱ�ǩ��
��ת��5�������������ϱ�ǩ��![]() ����ϵͳ��
����ϵͳ��![]() ��ת��6
��ת��6
4��ʱΪ![]() ʱ϶����ǩ���ɹ���ȡ��
ʱ϶����ǩ���ɹ���ȡ��![]() �Զ���1��ת��2
�Զ���1��ת��2
5 ��ʱΪ![]() ʱ϶��û�б�ǩ�ɹ����ͣ����д���W��ǩ��
ʱ϶��û�б�ǩ�ɹ����ͣ����д���W��ǩ��![]() �Զ���1��ת��3
�Զ���1��ת��3
6��ʱΪ![]() ʱ϶��û�б�ǩ�ɹ����͡����д���״̬A�ı�ǩ�������Ϊ�����Ӽ�������һ���Ӽ��ı�ǩ
ʱ϶��û�б�ǩ�ɹ����͡����д���״̬A�ı�ǩ�������Ϊ�����Ӽ�������һ���Ӽ��ı�ǩ![]() ��0����һ���Ӽ��ı�ǩ
��0����һ���Ӽ��ı�ǩ![]() ��1�����⣬���д���
��1�����⣬���д���![]() ��ǩ��
��ǩ��![]() Ҳ��1����һ��ʱ϶��ʼʱ��ת��3
Ҳ��1����һ��ʱ϶��ʼʱ��ת��3
7һ�������ڽ���
�����ϵ��㷨������Կ�������д�����ݱ�ǩ��PN��С���Ⱥ��ȡ��ǩ�ģ����ڱ�ǩ�ij�ʼ![]() ��������䣬��������Դ����ٱ�ǩ��ͻ�Ĵ�����������ֱ�ǩ��
��������䣬��������Դ����ٱ�ǩ��ͻ�Ĵ�����������ֱ�ǩ��![]() ��ͬ����������Բ��ò���6�ķ�ʽ�����¶Ա�ǩ��
��ͬ����������Բ��ò���6�ķ�ʽ�����¶Ա�ǩ��![]() ���з��䡣
���з��䡣
2.3 �㷨����
�����������ڣ���ǩ�ij�ʼ![]() �ű�������䣬��д�������ݱ�ǩ��
�ű�������䣬��д�������ݱ�ǩ��![]() �ŵĴ�С˳�����ζ�ȡ��ǩ��Ϣ������ǩ������ͬ��
�ŵĴ�С˳�����ζ�ȡ��ǩ��Ϣ������ǩ������ͬ��![]() ����ִ����Ӧ�ij�ͻ�ֽ⡣����������£���ȡ��ǩ��ʱ�佫���ǩ�ij�ͻʱ϶��������أ�����ͻʱ϶�������ǩ
����ִ����Ӧ�ij�ͻ�ֽ⡣����������£���ȡ��ǩ��ʱ�佫���ǩ�ij�ͻʱ϶��������أ�����ͻʱ϶�������ǩ![]() �ij�ʼ���������ء�ͼ1������������ǩ�����������ڱ���ȡ��ʾ��ͼ��ͼ�нڵ��Ա���˱�ǩ��
�ij�ʼ���������ء�ͼ1������������ǩ�����������ڱ���ȡ��ʾ��ͼ��ͼ�нڵ��Ա���˱�ǩ��![]() �͵�ǰʱ϶��
�͵�ǰʱ϶��![]() ��������ı�ǩ��ʾ�ڵ�ǰʱ϶��Ϊ״̬
��������ı�ǩ��ʾ�ڵ�ǰʱ϶��Ϊ״̬![]() ��ÿ���ڵ��֧�����������-1��0��1��ʾ�ˣ�Ӧ����ǩ��
��ÿ���ڵ��֧�����������-1��0��1��ʾ�ˣ�Ӧ����ǩ��![]() ���ӵ����֣��������ʾ��ϵͳ
���ӵ����֣��������ʾ��ϵͳ![]() ��
��![]() �ı仯����ͼ1(a)�����ǿ���������������ǩ��
�ı仯����ͼ1(a)�����ǿ���������������ǩ��![]() ��ͬ����˳�ͻʱ϶��Ӧ���࣬������ȡ������Ҫ6��ʱ϶��ʵ��������˻�Ϊ��ͳ�Ķ���������ͻ�㷨��ͼ1(b)�����˽�Ϊ����������������ǩ�ij�ʼ
��ͬ����˳�ͻʱ϶��Ӧ���࣬������ȡ������Ҫ6��ʱ϶��ʵ��������˻�Ϊ��ͳ�Ķ���������ͻ�㷨��ͼ1(b)�����˽�Ϊ����������������ǩ�ij�ʼ![]() �ž�����ͬ������������£�������
�ž�����ͬ������������£�������![]() ʱ϶��ֻ��
ʱ϶��ֻ��![]() ʱ϶�����(a)�ܵ�ʱ϶���١�
ʱ϶�����(a)�ܵ�ʱ϶���١�
��ͼ1�����ǿ��Կ����������������ں��ڶ�д�������ǵ����б�ǩ�����Զ�������Ψһ��![]() ������Щ
������Щ![]() ��
��![]() �������С���ˣ��ڵ�
�������С���ˣ��ڵ�![]() �ζ�����ʱ�����ޱ�ǩ�뿪��������������
�ζ�����ʱ�����ޱ�ǩ�뿪��������������![]() ��
��![]() ʱ϶�����б�ǩ�뿪����ֻ��
ʱ϶�����б�ǩ�뿪����ֻ��![]() ʱ϶�����б�ǩ��������ֻ����
ʱ϶�����б�ǩ��������ֻ����![]() ��ͬ�ı�ǩ������ͻ��ͼ2������������ǩ�ڵ�
��ͬ�ı�ǩ������ͻ��ͼ2������������ǩ�ڵ�![]() �ζ������ڣ��ޱ�ǩ�仯�����б�ǩ�仯ʱ�������
�ζ������ڣ��ޱ�ǩ�仯�����б�ǩ�仯ʱ�������
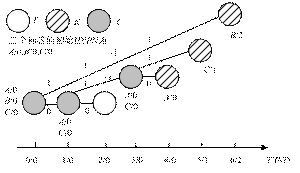
(a)��ǩPN����ͬ

(b)��ǩPN����ͬ
ͼ1 �������ڵ��㷨ִ��ʾ��ͼ

(a)

(b)
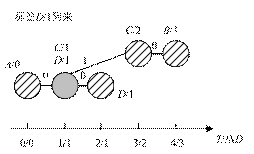
(c)

(d)
ͼ2 �����������㷨ִ��ʾ��ͼ
4 ���ܷ���
����1 ���ö��������γ�ͻ�㷨��ȡ![]() ����ǩ��ƽ��ʱ϶��Ϊ
����ǩ��ƽ��ʱ϶��Ϊ
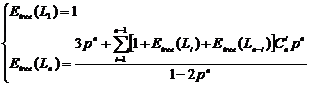 ��1��
��1��
����
![]() ��ѧ������
��ѧ������
![]() �ɹ���ȡ
�ɹ���ȡ![]() ����ǩ��Ҫ��ʱ϶����
����ǩ��Ҫ��ʱ϶����
![]() ��
��![]() ��Ԫ����ȡ
��Ԫ����ȡ![]() ��Ԫ�ص���������
��Ԫ�ص���������
![]() �����з�����ͻ�ı�ǩ��Ϊ���ͺ͵ȴ��ĸ��ʣ��ڶ����������㷨�У����ͺ͵ȴ��ĸ�����ͬ���Ҿ�Ϊ1/2��
�����з�����ͻ�ı�ǩ��Ϊ���ͺ͵ȴ��ĸ��ʣ��ڶ����������㷨�У����ͺ͵ȴ��ĸ�����ͬ���Ҿ�Ϊ1/2��
֤����ֻ��һ����ǩʱ�����ᷢ����ͻ�������![]() ��
��
��![]() >1ʱ���ɷ�Ϊ���������
>1ʱ���ɷ�Ϊ���������
1�������ݵı�ǩ��Ϊ0���ȴ���ǩ��Ϊ![]() ����ʱ�ĸ���Ϊ
����ʱ�ĸ���Ϊ![]() ������ʱ϶��Ϊ
������ʱ϶��Ϊ![]()
2�������ݵı�ǩ��Ϊ![]() ���ȴ���ǩ��Ϊ0����ʱ�ĸ���Ϊ
���ȴ���ǩ��Ϊ0����ʱ�ĸ���Ϊ![]() ������ʱ϶��Ϊ
������ʱ϶��Ϊ![]()
3�������ݵı�ǩ��![]() �ȴ���ǩ��Ϊ
�ȴ���ǩ��Ϊ![]() ����ʱ�ĸ���Ϊ
����ʱ�ĸ���Ϊ![]() ������ʱ϶��Ϊ
������ʱ϶��Ϊ![]() ����ˣ�������
����ˣ�������
![]()
����ϲ����֤��
3.1��������
����1 ��![]() ����ǩ�ij�ʼ���ȼ����������Ϊ0-
����ǩ�ij�ʼ���ȼ����������Ϊ0-![]() ��������������Զ����ȼ������㷨�������������ڳɹ���ȡ
��������������Զ����ȼ������㷨�������������ڳɹ���ȡ![]() ����ǩ�����ƽ��ʱ϶��Ϊ
����ǩ�����ƽ��ʱ϶��Ϊ
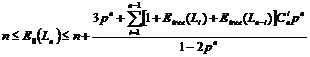 ��2��
��2��
֤�����ɹ���ȡ![]() ����ǩ�����ƽ��ʱ϶����Ҫ���ǩ������ij�ʼ���ȼ����йأ����Դ������������������
����ǩ�����ƽ��ʱ϶����Ҫ���ǩ������ij�ʼ���ȼ����йأ����Դ������������������
1��![]() ����ǩ�ij�ʼ���ȼ��ž����ظ��ط���Ϊ0-
����ǩ�ij�ʼ���ȼ��ž����ظ��ط���Ϊ0-![]() ʱ�������ʱ϶�����٣���ʱ
ʱ�������ʱ϶�����٣���ʱ![]()
2��![]() ����ǩ�ij�ʼ���ȼ��ž�Ϊ
����ǩ�ij�ʼ���ȼ��ž�Ϊ![]() ʱ�������ʱ϶����࣬��ʱ��ʱ϶��ӦΪ
ʱ�������ʱ϶����࣬��ʱ��ʱ϶��ӦΪ![]() ��
��![]() ʱ϶�Ͳ��ö����������㷨��ȡ
ʱ϶�Ͳ��ö����������㷨��ȡ![]() ����ǩ����ʱ϶֮�ͣ����
����ǩ����ʱ϶֮�ͣ����![]() ��
��
����������������������ݣ�1��ʽ����2��ʽ��֤��
3.2����������
����2�Զ����ȼ������㷨�ڵ�![]() ���������ڣ��ɹ���ȡ
���������ڣ��ɹ���ȡ![]() ����ǩ�����ƽ��ʱ϶��Ϊ
����ǩ�����ƽ��ʱ϶��Ϊ
![]() (3)
(3)
֤��������2.2���㷨���裬��֪��![]() ����ǩ�����������ڱ��ɹ���ȡ�������ȼ����Զ�����Ϊ
����ǩ�����������ڱ��ɹ���ȡ�������ȼ����Զ�����Ϊ![]() ������ڵ�
������ڵ�![]() �ζ�ȡ��ǩʱ�����ȼ��ֱ�Ϊ
�ζ�ȡ��ǩʱ�����ȼ��ֱ�Ϊ![]() �ı�ǩ�����δ������ݣ���ʱ�����ʱ϶��Ϊ
�ı�ǩ�����δ������ݣ���ʱ�����ʱ϶��Ϊ![]() ����
����
����3�ڵ�![]() �������ڿ�ʼʱ��ԭ
�������ڿ�ʼʱ��ԭ![]() ����ǩ����
����ǩ����![]() ����ǩ�뿪�������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶��
����ǩ�뿪�������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶��
![]() (4)
(4)
֤��������![]() ����ǩ�뿪ʱ����
����ǩ�뿪ʱ����![]() ���������ڽ�����
���������ڽ�����![]() ��Eʱ϶������ȡ
��Eʱ϶������ȡ![]() ����ǩ����Ҫ
����ǩ����Ҫ![]() ��ʱ϶�������ܹ���Ҫ
��ʱ϶�������ܹ���Ҫ![]() ��ʱ϶����֤��
��ʱ϶����֤��
����4�ڵ�![]() �������ڿ�ʼʱ��ԭ
�������ڿ�ʼʱ��ԭ![]() ����ǩ����
����ǩ����![]() ����ǩ�����������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶������
����ǩ�����������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶������
![]() (5)
(5)
֤��������![]() ����ǩ����ʱ�������ʱ϶����������ǣ�
����ǩ����ʱ�������ʱ϶����������ǣ�![]() ����ǩ�����ȼ���
����ǩ�����ȼ���![]() ����ǩ�е�һ����ͬ����ʱ�����ʱ϶��Ϊ
����ǩ�е�һ����ͬ����ʱ�����ʱ϶��Ϊ![]() ����֤��
����֤��
����5�ڵ�![]() �������ڿ�ʼʱ��ԭ
�������ڿ�ʼʱ��ԭ![]() ����ǩ����
����ǩ����![]() ����ǩ�뿪
����ǩ�뿪![]() ����ǩ�����������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶������
����ǩ�����������Զ����ȼ������㷨��ȡ���б�ǩ��ƽ��ʱ϶������
![]() (6)
(6)
֤������(4)��(5)��֤��
3.3������������㷨�ıȽ�
����6 ����ǩ���㹻��ʱ�������Զ����ȼ������㷨�ɹ���ȡ��ǩ����ƽ��ʱ϶��������ڶ����������㷨
֤�������Է�Ϊ���������֤�����ֱ���
1��ǩ���ƶ�
��ʽ(2)��֪���ڵ�0�����ڲ����Զ����ȼ������㷨�ɹ���ȡ��ǩ�����ƽ��ʱ϶������![]() ����
����![]() �ϴ�ʱ��������
�ϴ�ʱ��������![]() ����ʱ��
����ʱ��![]() ��
��![]() �����
�����
![]() (7-a)
(7-a)
��(2)��֪���ڵ�![]() �����ڲ����Զ����ȼ������㷨�ɹ���ȡ��ǩ�����ƽ��ʱ϶������
�����ڲ����Զ����ȼ������㷨�ɹ���ȡ��ǩ�����ƽ��ʱ϶������![]() ������(7-a)�ɵ�
������(7-a)�ɵ�![]() �����
�����
![]() (7-b)
(7-b)
2��ǩ���ƶ�
���ڵ�![]() �������ڿ�ʼʱ��ԭ
�������ڿ�ʼʱ��ԭ![]() ����ǩ��
����ǩ��![]() ����ǩ�뿪
����ǩ�뿪![]() ����ǩ��������Ϊ
����ǩ��������Ϊ![]() �㹻������
�㹻������![]() ������Ϊ
������Ϊ![]() �����Եõ�
�����Եõ�![]() �����ݶ���5�����Եõ�
�����ݶ���5�����Եõ�
![]() (7-c)
(7-c)
�ۺ�(7-a)-(7-c)����֤��
4 ����������
�������Dz��÷������飬�����ĵ��㷨������������㷨���Աȣ����������㷨��һ���������ڶ�ȡ���б�ǩ�����ʱ϶�����������Monte-Karlo���������н���ɶ�������50������ȡƽ���õ������Զ����ȼ�������㷨�У��ٶ���ǩ��Ŀ��Ϊ��֪��![]() Ϊ��ǩ��Ŀ����
Ϊ��ǩ��Ŀ����![]() ����
����![]() ʱ��һ�������ڽ��������⣬��ǩ�ij�ʼ
ʱ��һ�������ڽ��������⣬��ǩ�ij�ʼ![]() Ϊ0-
Ϊ0-![]() ������������������Ƿֱ���������������������
������������������Ƿֱ���������������������
4.1��ǩ���ƶ�
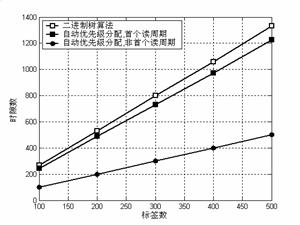
��ǩ���ƶ�ָ���ǣ�û���µı�ǩ������Ҳ�ޱ�ǩ�뿪��ͼ3�����˱�ǩ���ƶ�ʱ��ʱ϶�����ǩ���仯��������㷨�Աȡ���ͼ�п��Կ����������������ڣ��Զ����ȼ������ʱ϶��Ҫ���ڶ��������㷨���ر�أ������ű�ǩ��Ŀ��������������㷨��ȣ������ʱ϶�����١���ԭ���ǣ����Զ����ȼ������㷨�У�ÿ����ǩ����������һ����ʼ![]() �ţ���Ȼ��
�ţ���Ȼ��![]() ����ͬ����������ǣ�������������㷨��ȣ���ͻʱ϶���������١��ڷ����������ڣ�����������㷨��ȣ��Զ����ȼ����������ʱ϶����һ�����٣�������Ϊ���ھ������������ڣ���ǩ��
����ͬ����������ǣ�������������㷨��ȣ���ͻʱ϶���������١��ڷ����������ڣ�����������㷨��ȣ��Զ����ȼ����������ʱ϶����һ�����٣�������Ϊ���ھ������������ڣ���ǩ��![]() ���Զ�����Ϊ0,1,2,��
���Զ�����Ϊ0,1,2,��![]() ����������֮���������ֻ��Ҫ
����������֮���������ֻ��Ҫ![]() �����ڡ�
�����ڡ�
4.2��ǩ���ƶ�
��ǩ���ƶ������Ҳ����������������ֱ����б�ǩ�뿪���б�ǩ������ͬʱ�б�ǩ�뿪�������������뿪�͵����ı�ǩ��![]() ��������ģ����Ҿ��ٶ�ԭ��ǩ��Ŀ
��������ģ����Ҿ��ٶ�ԭ��ǩ��Ŀ![]() =300��
=300��
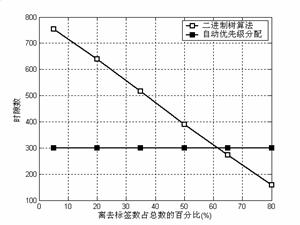
ͼ4����������ʱ϶������ȥ��ǩ�仯���㷨�ԱȽ������ͼ�п��Կ���������ȥ�ı�ǩ�������仯ʱ���Զ����ȼ����������ʱ϶���仯������������Ϊ�����б�ǩ��ȥʱ�����ºܶ��ʱ϶�������ڶ��������㷨������ǩ��ȥ���ܵı�ǩ�����٣������ʱ϶��Ҳ��Ȼ���١���ͼ�л����Կ�������ǩ�뿪����Ŀ����60%����ʱ�������������㷨����ʱ϶������ʼ�����Զ����ȼ����䡣
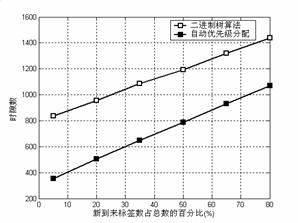
ͼ5���������µı�ǩ����ʱ����ʱ϶���ı仯���������������£��Զ����ȼ������ʱ϶���������ڶ����������㷨�����Զ����ȼ������㷨�У�ԭ���ı�ǩ�����״ζ����ں�![]() �ѱ��Զ����䣬���б�ǩ����ʱ����ͻʱ϶ֻ�����ڵ������ı�ǩ
�ѱ��Զ����䣬���б�ǩ����ʱ����ͻʱ϶ֻ�����ڵ������ı�ǩ![]() ��ԭ����ǩ
��ԭ����ǩ![]() ��ͬʱ���������ڶ����������㷨���ܵ�ʱ϶����С��
��ͬʱ���������ڶ����������㷨���ܵ�ʱ϶����С��
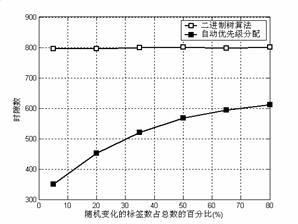
ͼ6�����ˣ�ͬʱ�б�ǩ�뿪�͵���ʱ������ʱ϶���ı仯�������������Ǽٶ���ǩ�뿪���ͱ�ǩ��������ͬ�����ܵı�ǩ�����䡣�����ܵı�ǩ�����䣬��˶��������㷨�����ʱ϶��Ҳ���䡣�������Զ����ȼ������㷨�������뿪�͵�����ǩ�������࣬![]() ʱ϶��
ʱ϶��![]() ʱ϶���������ӣ��������ʱ϶��Ҳ�����ӣ������ᳬ�������������㷨��
ʱ϶���������ӣ��������ʱ϶��Ҳ�����ӣ������ᳬ�������������㷨��
ͼ3 �ޱ�ǩ�ƶ�ʱ�㷨�Ա�
ͼ4 �б�ǩ��ȥʱ���㷨�Ա�
ͼ5 �б�ǩ����ʱ���㷨�Ա�
ͼ6 ͬʱ�б�ǩ��������ȥʱ���㷨�Ա�
6 ����
���Զ����ȼ������㷨�У�ÿ����ǩ����ʼ����һ��![]() �ţ�����һ�ζ����ں����б�ǩ��
�ţ�����һ�ζ����ں����б�ǩ��![]() �������η���Ϊ0,1,��
�������η���Ϊ0,1,��![]() �����֮������ڣ�����ʱ϶��ֻ��
�����֮������ڣ�����ʱ϶��ֻ��![]() ������������֤��������ǩ���㹻��ʱ���Զ����ȼ������㷨�����ʱ϶��������ڶ����������㷨���ӷ������У����ǿ��Եõ�������ǩ���ޱ仯ʱ������������㷨��ȣ��Զ����ȼ������㷨���������ںͷ����������ڣ������ʱ϶������С�����б�ǩ�뿪ʱ�����������㷨�����ʱ϶���仯����ͬʱ������ȥ��ǩ�����࣬����ʱ϶�������ڶ��������㷨�����б�ǩ����ʱ���Զ����ȼ������㷨����ʱ϶���������ڶ��������㷨����ͬʱ�б�ǩ�뿪�͵���ʱ���Զ����ȼ������㷨����ʱ϶������仯��ǩ����Ŀ��������࣬���Բ��ᳬ�������������㷨��
������������֤��������ǩ���㹻��ʱ���Զ����ȼ������㷨�����ʱ϶��������ڶ����������㷨���ӷ������У����ǿ��Եõ�������ǩ���ޱ仯ʱ������������㷨��ȣ��Զ����ȼ������㷨���������ںͷ����������ڣ������ʱ϶������С�����б�ǩ�뿪ʱ�����������㷨�����ʱ϶���仯����ͬʱ������ȥ��ǩ�����࣬����ʱ϶�������ڶ��������㷨�����б�ǩ����ʱ���Զ����ȼ������㷨����ʱ϶���������ڶ��������㷨����ͬʱ�б�ǩ�뿪�͵���ʱ���Զ����ȼ������㷨����ʱ϶������仯��ǩ����Ŀ��������࣬���Բ��ᳬ�������������㷨��
�ο����ף�
1 K. Finkenzeller, RFID
Handbook: Radio-Frequncy Indetification Fundamentals and Applications in
Contactless Smart Cards and Identification, Second Edition, Jhon Wiley,
2 D.H. Shih, P. L. Sun, D. C. Yen,
S.M. Huang, Taxonomy and survey of RFID anti-collision protocols, ELSEVIER, Computer
communications,2006, Vol.29,. No.11, pp.2150-2166
3 Vogt H.
Multiple object identification with passive RFID tags. IEEE International
Conference on Systems, Man and. Cybernetics, Vol. 3, October 2002.
4 D. R. Hush
and C. Wood, Analysis of tree algorithm for RFID arbitration, Proc. of IEEE International Symposium on
Information Theory, pp. 107, 1998.
6
Capetanakis, J. I. Tree Algorithms for Packet. Broadcast Channels. IEEE
Transactions on. Information Theory, vol. IT-25, no. 5, Sept. 1979, pp.
505�C515.
����飺
�⺣�棬�У�1977������2007��������������豸��������˾����ɽ��ѧ������
��λ��������������о�Ժ
��ַ��������������·6��
�ʱࣺ650051
�绰��13668706480��0871-8326193
Email��wuhaifeng@mail.ksec.cn.